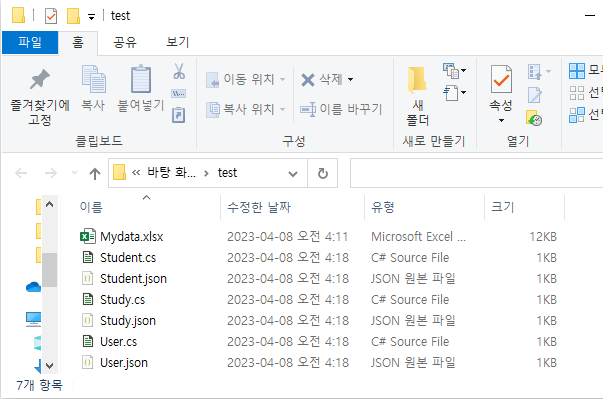
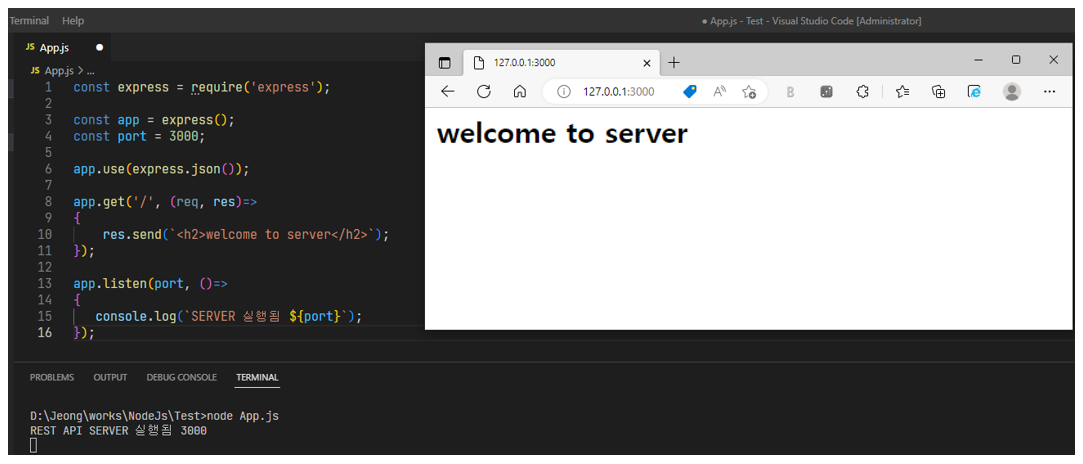
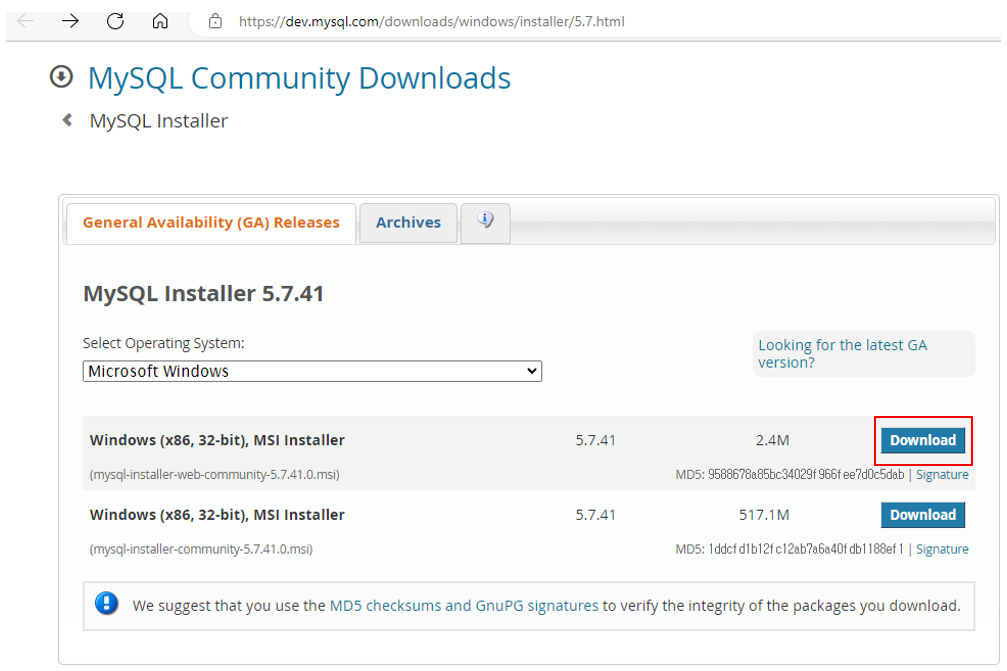
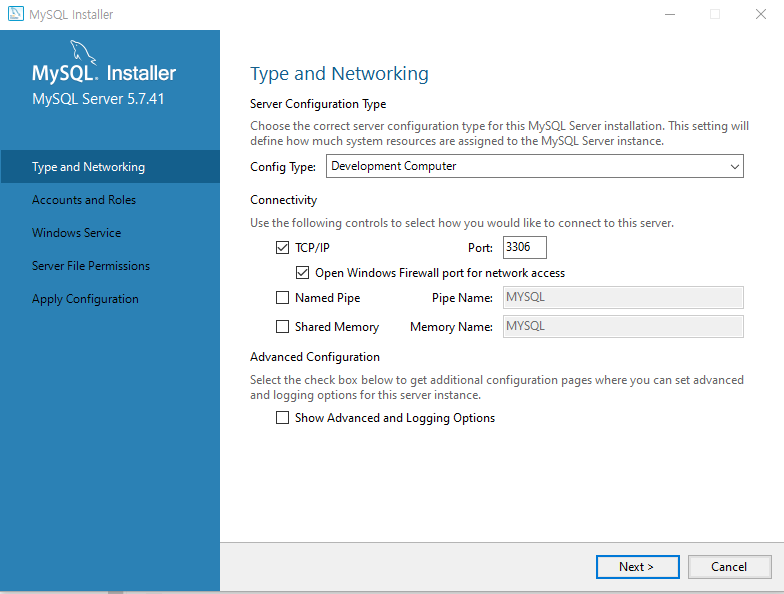
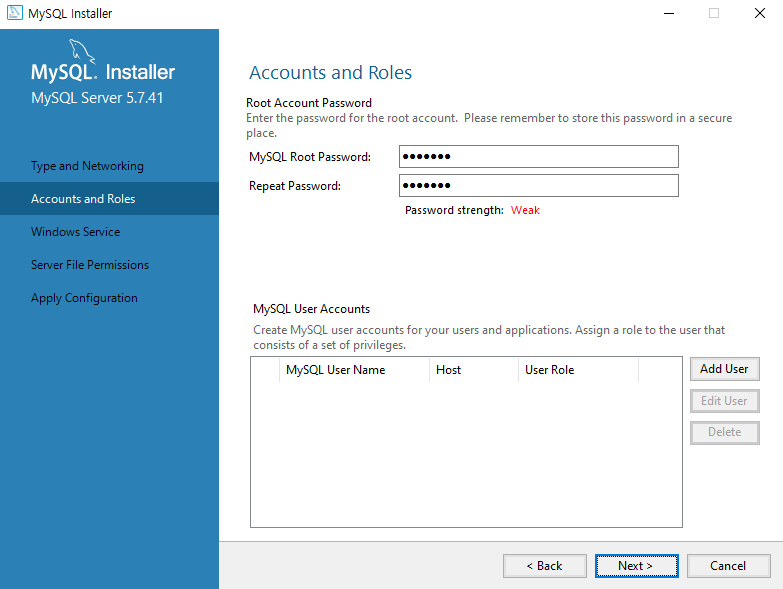
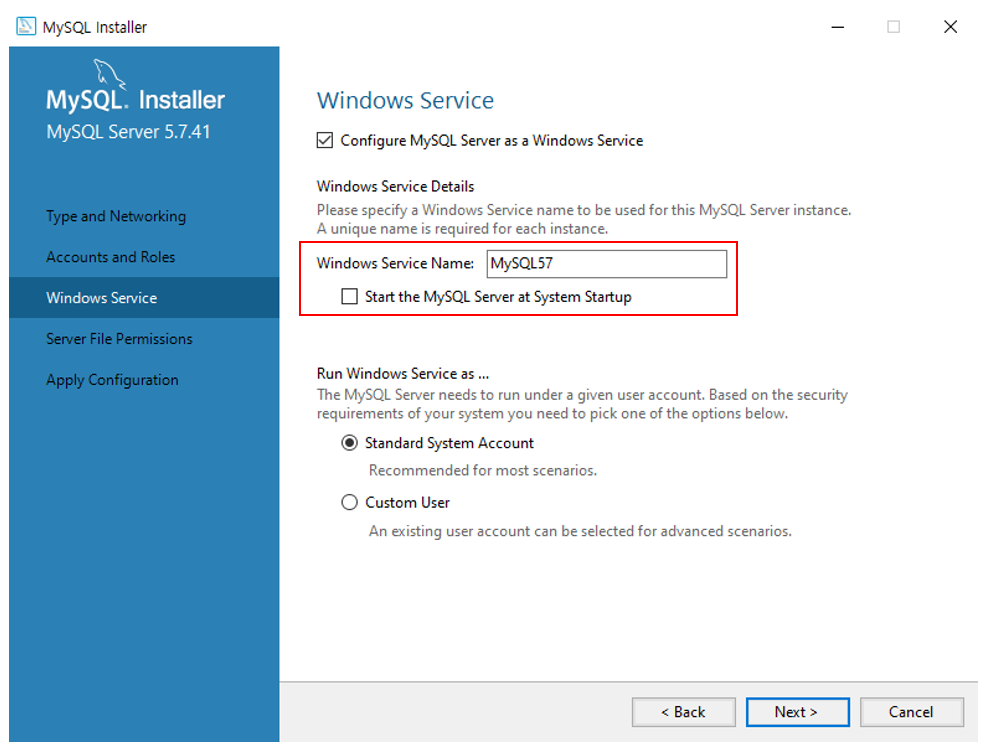
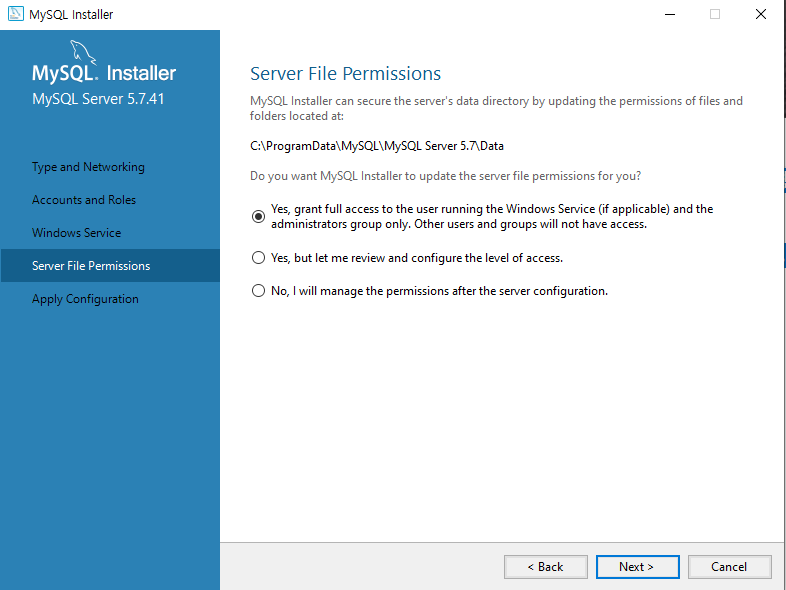
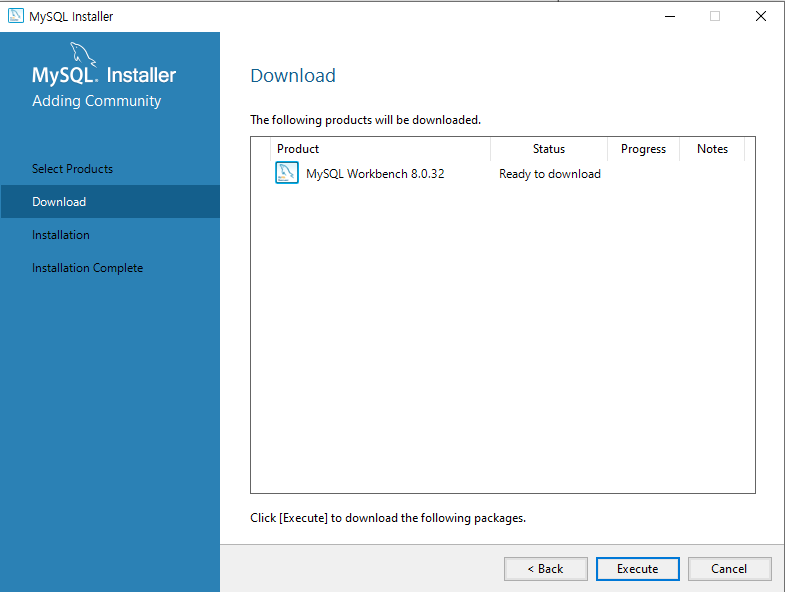
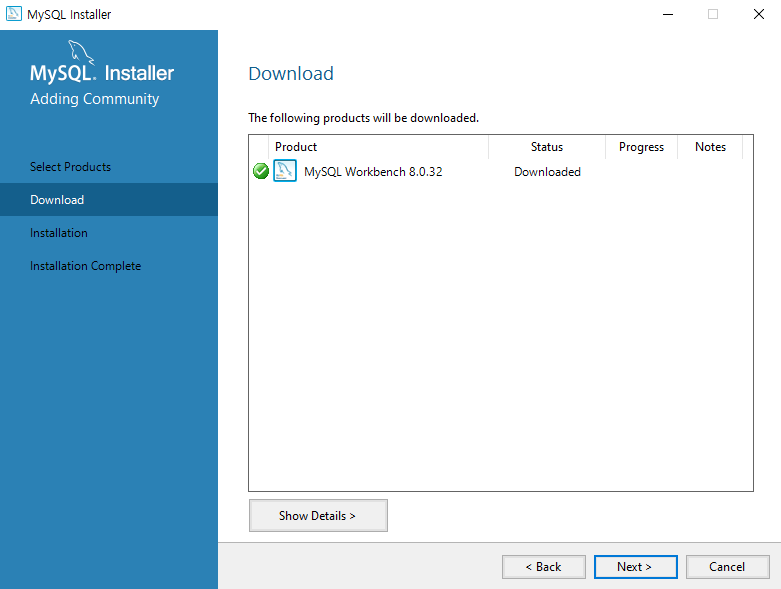
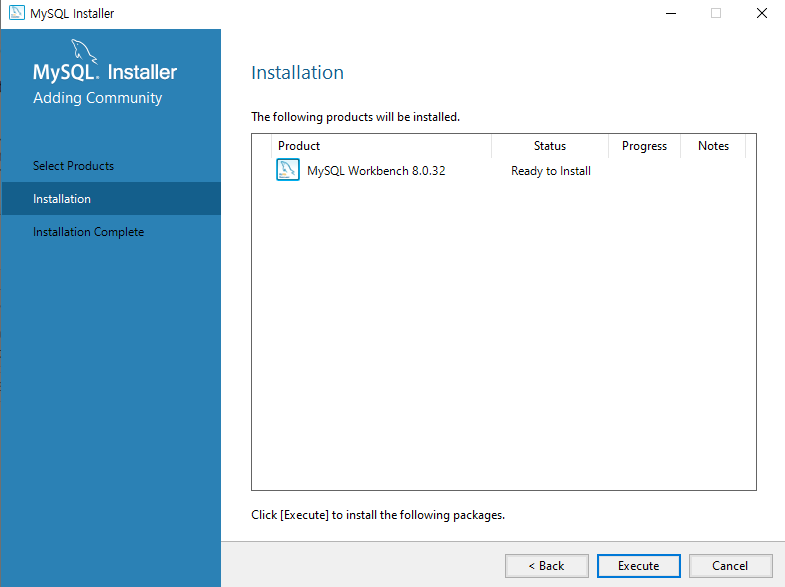
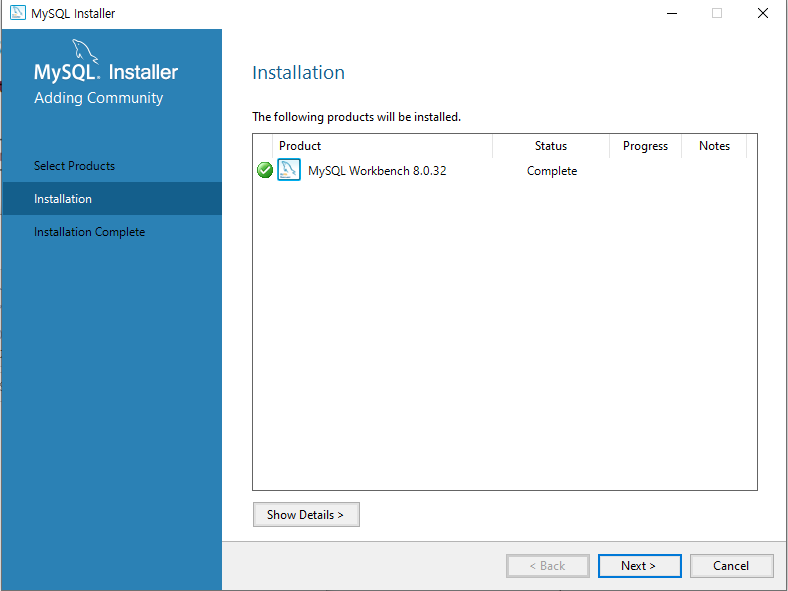
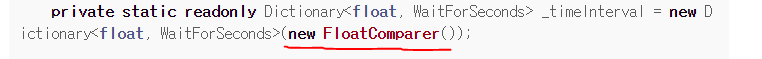uidMap이라는 map 자료구조는 유저 아이디를 key로, 유저의 닉네임을 value로 저장합니다. uidRecord라는 벡터는 각 로그마다 유저 아이디와 해당 로그 메시지를 pair로 묶어 저장하는 용도로 사용됩니다.
for 루프에서는 record 벡터의 각 로그를 분리하여 command, uid, nickname 변수에 저장합니다. command 변수는 로그 유형을, uid 변수는 유저 아이디를, nickname 변수는 유저의 닉네임을 나타냅니다.
로그 유형에 따라 다음과 같은 처리를 수행합니다.
Enter: uidMap에 해당 유저 아이디가 이미 존재하는 경우에는 닉네임을 업데이트하고, 존재하지 않는 경우에는 새로 추가합니다. 그리고 uidRecord 벡터에 유저 아이디와 "님이 들어왔습니다."라는 메시지를 pair로 묶어 추가합니다. Leave: uidRecord 벡터에 유저 아이디와 "님이 나갔습니다."라는 메시지를 pair로 묶어 추가합니다. Change: uidMap에 해당 유저 아이디가 존재하는 경우에는 닉네임을 업데이트합니다. uidRecord 벡터에 추가된 pair들은 마지막 for 루프에서 uidMap을 참조하여 출력 문자열을 생성하고, answer 벡터에 추가됩니다.
코드를 자세히 살펴보면, 우선 record라는 vector<string>을 입력값으로 받아들입니다. 이 record는 각 로그를 문자열 형태로 저장하고 있습니다. 이후 uidMap이라는 map 자료구조와 uidRecord라는 vector<pair> 자료구조를 선언해줍니다.
이후 record의 크기만큼 반복문을 실행하면서, split 함수를 이용하여 로그를 공백 단위로 분리해줍니다. 이 분리된 로그를 기반으로 각 로그에 따른 처리를 해줍니다.
만약 Enter 명령어가 들어온다면, 해당 유저가 기존에 존재하는 유저인지 신규 유저인지를 판단하여 uidMap에 저장합니다. 또한, uidRecord에는 해당 유저가 들어왔음을 기록해줍니다.
만약 Leave 명령어가 들어온다면, 해당 유저가 나갔음을 uidRecord에 기록해줍니다.
만약 Change 명령어가 들어온다면, uidMap에 해당 유저의 닉네임을 변경해줍니다.
이렇게 각 로그에 대한 처리를 마친 후, uidRecord에 저장된 로그 정보와 uidMap에 저장된 유저 정보를 기반으로 최종적인 출력 값을 만들어냅니다. uidRecord의 크기만큼 반복문을 실행하면서, uidMap에서 해당 유저의 닉네임을 가져와 로그와 함께 출력 값을 만들어 answer vector에 push_back 해줍니다.
3. 코드
#include <string>
#include <vector>
#include <map>
#include <sstream>
using namespace std;
//https://www.lifencoding.com/language/22#post?p=1
vector<string> split(string str, char Delimiter)
{
istringstream iss(str); // istringstream에 str을 담는다.
string buffer; // 구분자를 기준으로 절삭된 문자열이 담겨지는 버퍼
vector<string> result;
// istringstream은 istream을 상속받으므로 getline을 사용할 수 있다.
while (getline(iss, buffer, Delimiter))
{
result.push_back(buffer); // 절삭된 문자열을 vector에 저장
}
return result;
}
vector<string> solution(vector<string> record)
{
vector<string> answer;
map<string, string> uidMap;
vector<pair<string, string>> uidRecord;
int recordSize = record.size();
for (int i = 0; i < recordSize; i++)
{
vector<string> splitStr = split(record[i], ' ');
string command = splitStr[0];
string uid = splitStr[1];
if (command == "Enter")
{
string nickname = splitStr[2];
// 기존 유저
if (uidMap.find(uid) != uidMap.end())
uidMap[uid] = nickname;
// 신규 유저
else
uidMap.insert({uid, nickname});
uidRecord.push_back({uid, "님이 들어왔습니다."});
}
else if (command == "Leave")
{
uidRecord.push_back({ uid, "님이 나갔습니다." });
}
else if (command == "Change")
{
string nickname = splitStr[2];
if (uidMap.find(uid) != uidMap.end())
uidMap[uid] = nickname;
}
}
int uidRecordSize = uidRecord.size();
for (int i = 0; i < uidRecordSize; i++)
{
answer.push_back(uidMap[uidRecord[i].first] + uidRecord[i].second);
}
return answer;
}
XLua는 C#과 Lua 스크립트를 결합하여 Unity 프로젝트에서 스크립트를 작성할 수 있도록 지원하는 라이브러리예요. XLua는 Lua 스크립트 엔진과 C# 언어 간의 인터페이스를 제공하여, Lua 스크립트와 C# 클래스 간의 데이터 전송 및 상호 작용을 쉽게 할 수 있도록 도와줘요. 이를 통해 C# 언어의 장점과 Lua 스크립트 언어의 장점을 모두 활용하여 Unity 게임 개발을 더욱 효율적으로 할 수 있어요.
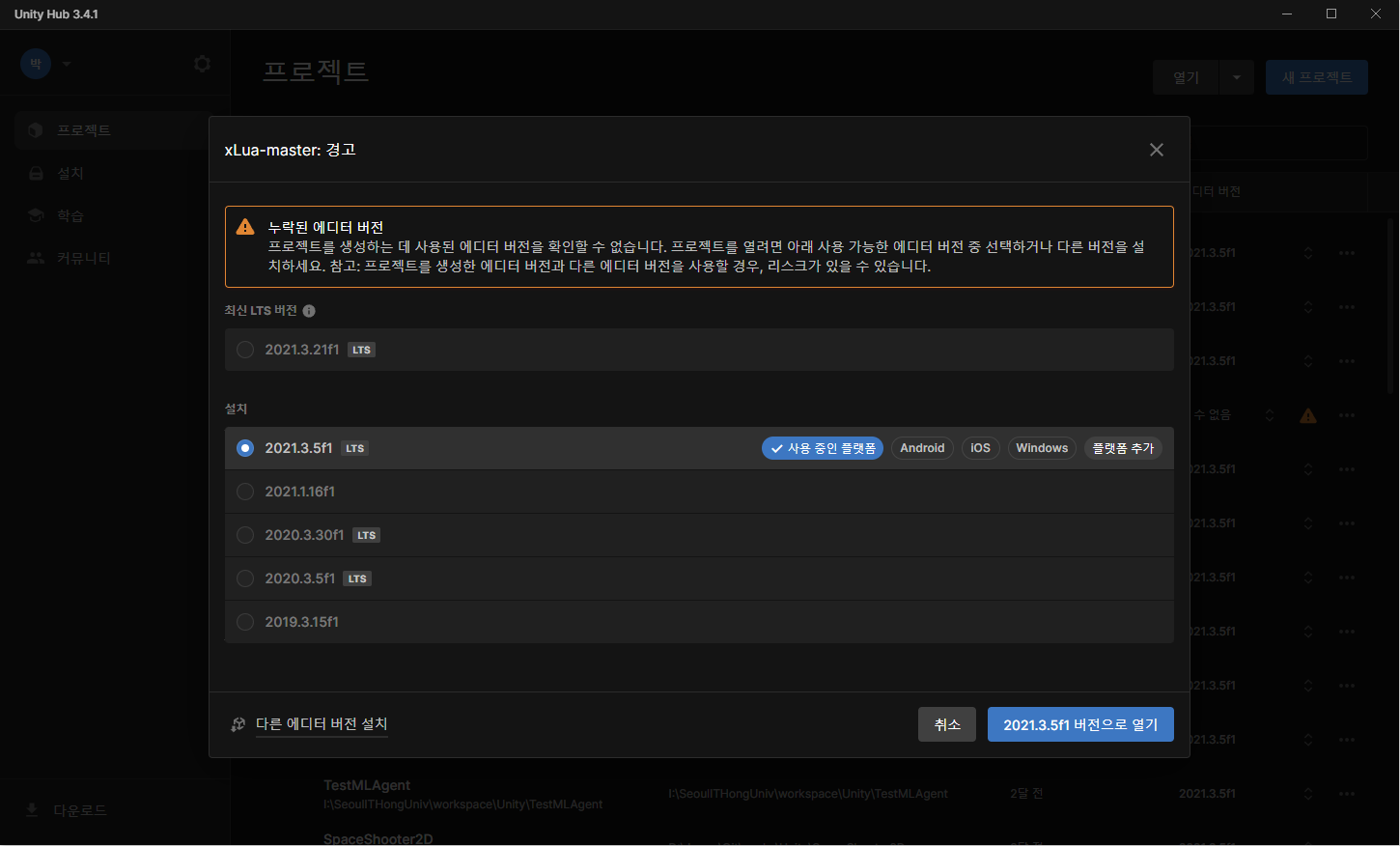
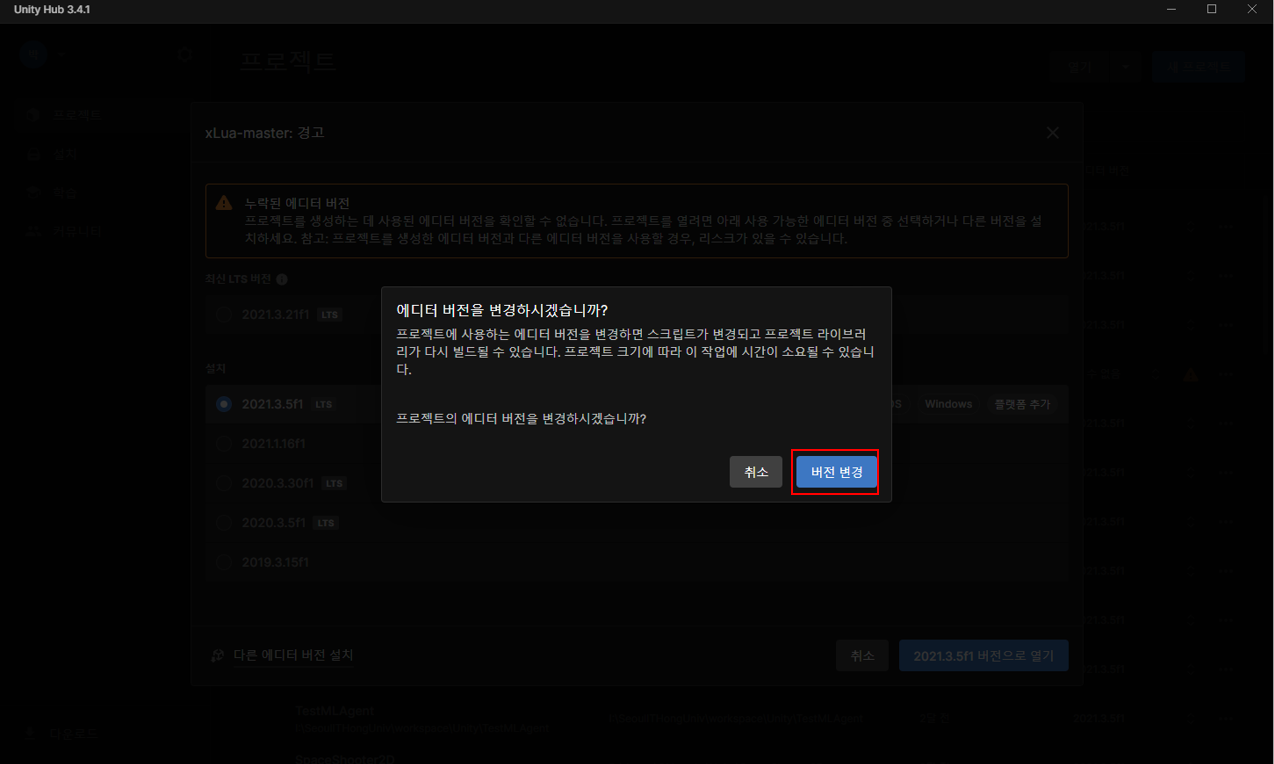
이렇게 에디터 버전이 누락됐다고 나오는데 전 그냥 설치되어 있는 2021.3.5f1 버전으로 열었어요.
'Continue' 클릭
이렇게 잘 열렸다면 성공이에요.
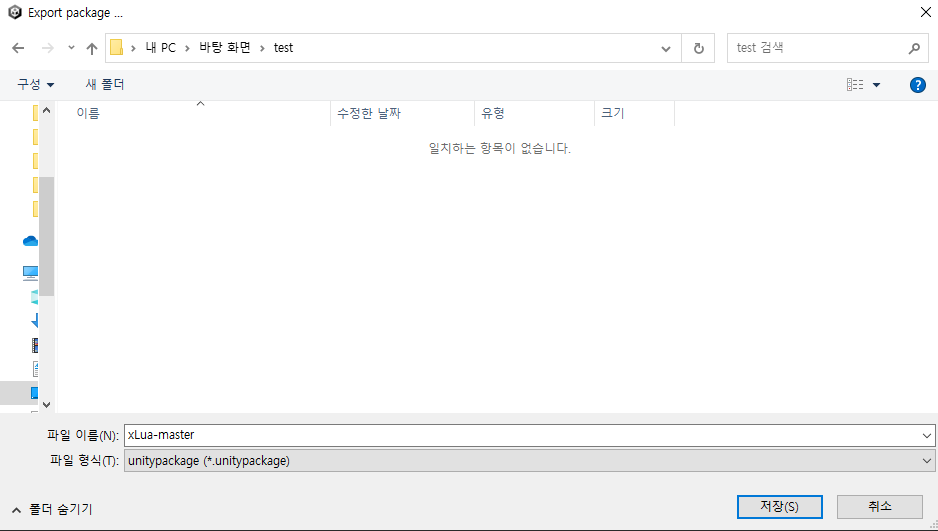
2.3 프로젝트 유니티패키지로 뽑아내기
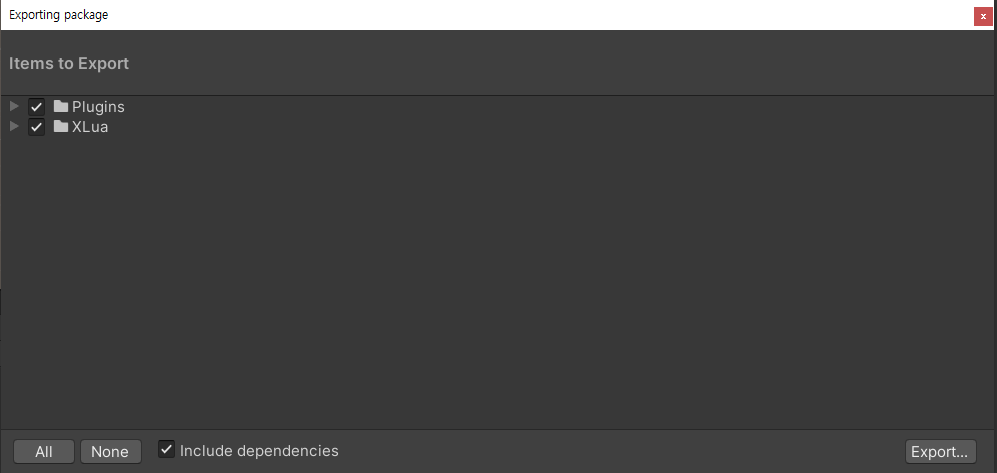
에셋 폴더에서 우클릭을 해서 'Export Package...' 을 클릭해서 유니티 패키지를 생성해요.
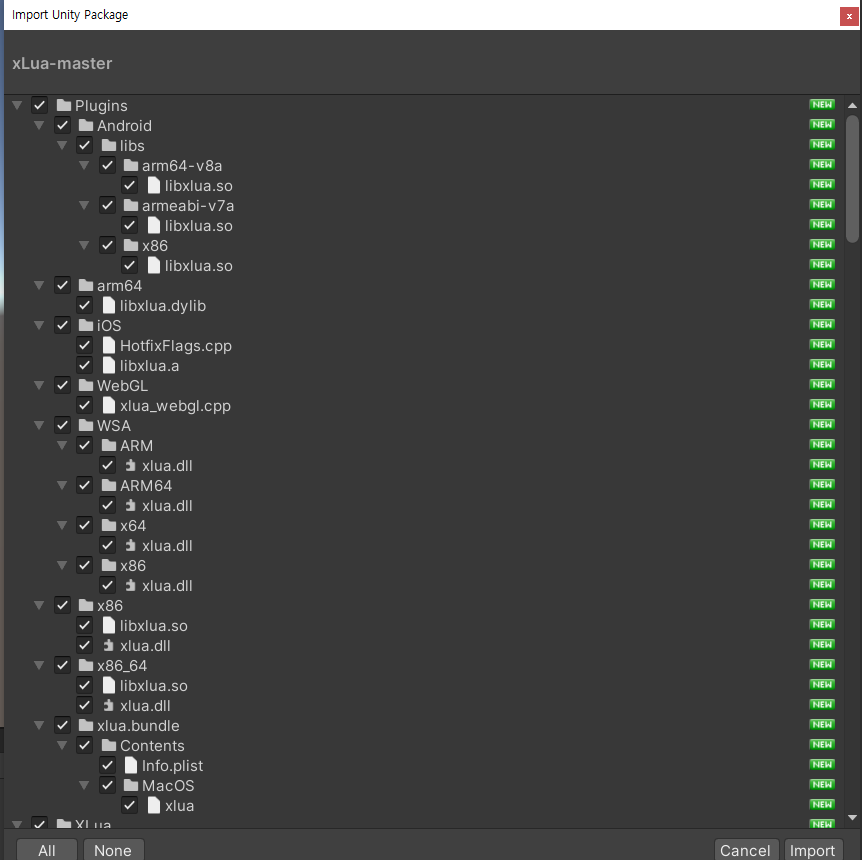
준비는 끝났어요. 이제 저희 프로젝트에 이 패키지를 임포트 하면 돼요.
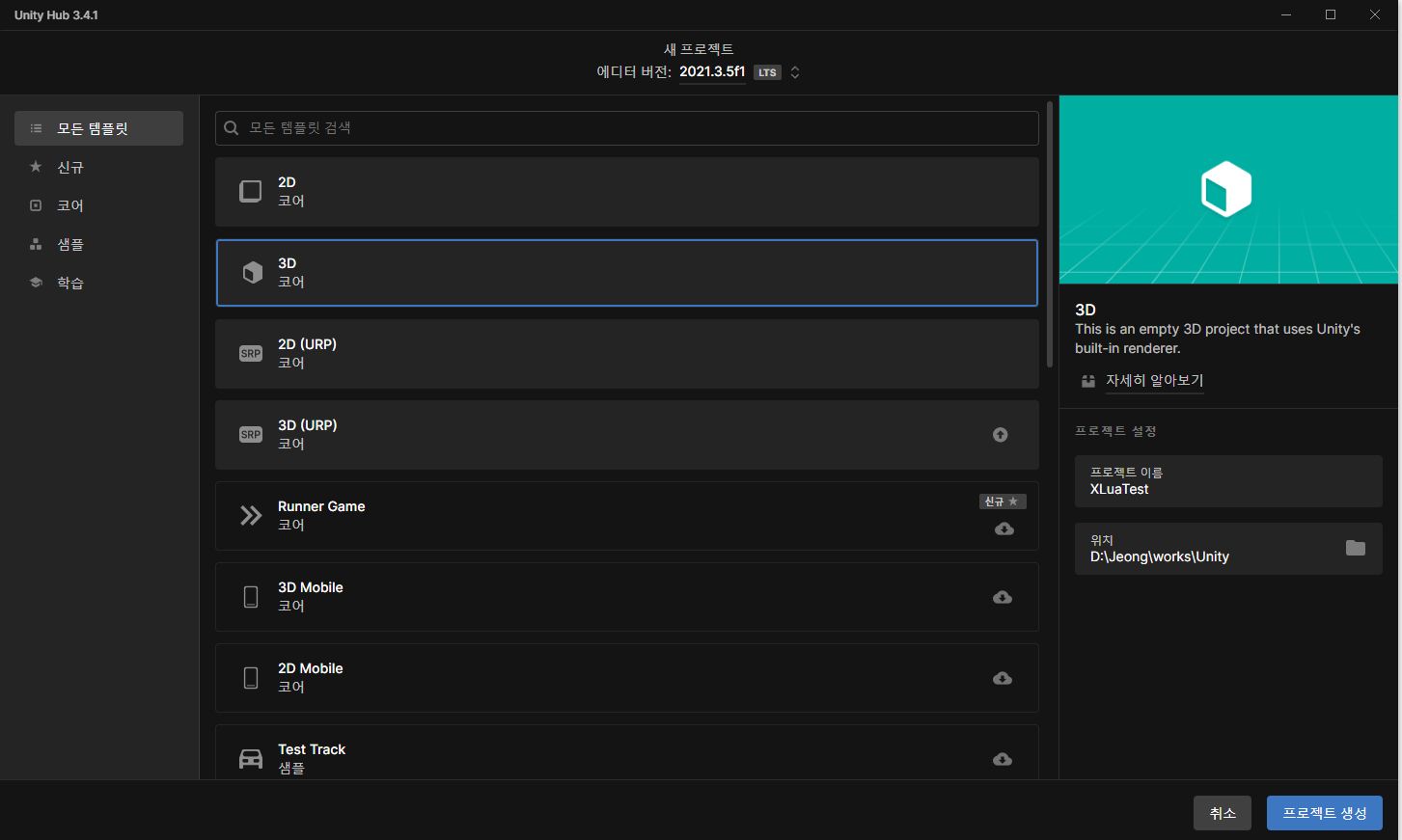
2.4 새 프로젝트 생성
저는 3D 프로젝트를 만들어서 테스트했어요.
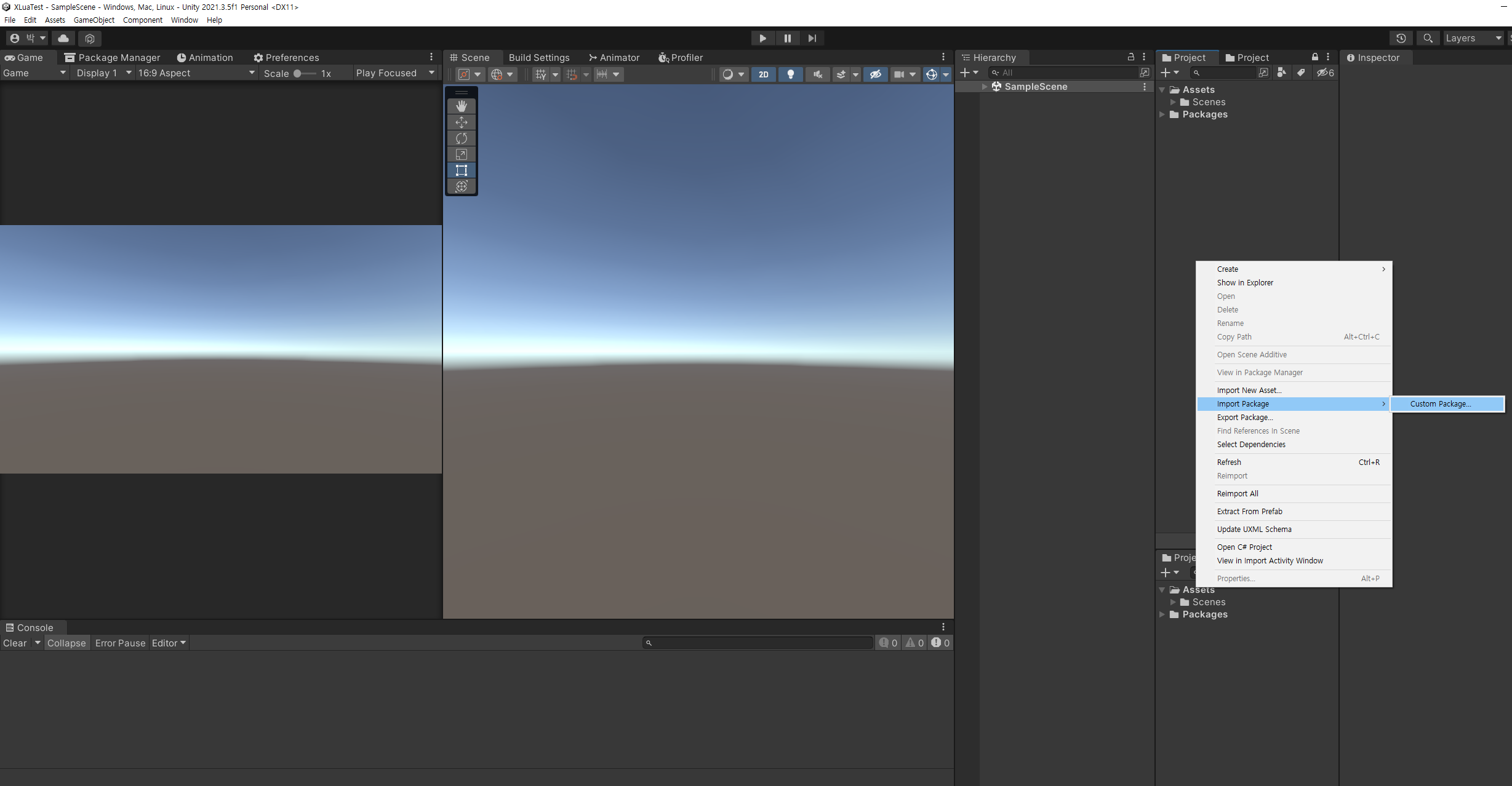
2.5 xLua 패키지 임포트 하기
생성된 프로젝트에 아까 뽑아낸 유니티 패키지를 임포트 해줘요.
상단에 XLua가 표시되면 정상적으로 설치가 된 거예요.
3. Lua 스크립트 작성하기
이제 Lua 스크립트를 작성해야 하는데 마우스 우클릭 했을 때 C# 스크립트처럼 Create 메뉴에 Lua스크립트가 없어서 이거 먼저 메뉴버튼을 만들어 줬어요.
XLuaMenuEditor.cs
using UnityEditor;
using System.IO;
public class XLuaMenuEditor : Editor
{
[MenuItem("Assets/Create/Lua Script")]
private static void CreateLuaScript()
{
string path = AssetDatabase.GetAssetPath(Selection.activeObject);
if (path == "")
{
path = "Assets";
}
else if (Path.GetExtension(path) != "")
{
path = path.Replace(Path.GetFileName(AssetDatabase.GetAssetPath(Selection.activeObject)), "");
}
// 새 텍스트 파일을 생성
string fileName = "NewLuaScript.lua.txt";
int fileIndex = 0;
while (File.Exists(Path.Combine(path, fileName)))
{
fileIndex++;
fileName = "NewLuaScript" + fileIndex + ".lua.txt";
}
// 파일 생성 후 이름 변경
string newFilePath = Path.Combine(path, fileName);
File.Create(newFilePath).Dispose();
AssetDatabase.Refresh();
}
}
이제 'Lua Script'를 클릭하면 루아 스크립트 파일이 생성돼요.
간단하게 유니티 Debug.Log()를 찍는 코드를 작성해볼게요.
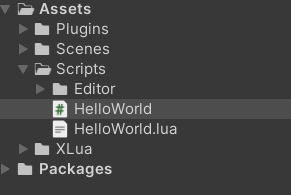
HelloWorld.cs와, HelloWorld.lua.txt 파일을 만들어요.
Helloworld.cs
using UnityEngine;
using XLua;
using System;
[LuaCallCSharp]
public class HelloWorld : MonoBehaviour
{
public TextAsset luaScript;
internal static LuaEnv luaEnv = new LuaEnv(); //all lua behaviour shared one luaenv only!
private Action luaStart;
private Action luaUpdate;
private Action luaOnDestroy;
float delta = 0;
private LuaTable scriptEnv;
void Start()
{
Init();
}
void Update()
{
if (luaUpdate == null && Input.GetKeyDown(KeyCode.G))
{
Init();
}
if (luaUpdate != null)
{
delta += Time.deltaTime;
luaUpdate();
}
if (luaUpdate != null && delta >= 3)
{
DestroyLua();
}
}
void Init()
{
delta = 0;
scriptEnv = luaEnv.NewTable();
LuaTable meta = luaEnv.NewTable();
meta.Set("__index", luaEnv.Global);
scriptEnv.SetMetaTable(meta);
meta.Dispose();
scriptEnv.Set("self", this);
luaEnv.DoString(luaScript.text, "HelloWorld", scriptEnv);
scriptEnv.Get("start", out luaStart);
scriptEnv.Get("update", out luaUpdate);
scriptEnv.Get("ondestroy", out luaOnDestroy);
if (luaStart != null)
{
luaStart();
}
}
void DestroyLua()
{
if (luaOnDestroy != null)
{
luaOnDestroy();
}
luaOnDestroy = null;
luaUpdate = null;
luaStart = null;
scriptEnv.Dispose();
}
}
저도 공부하는 중이라 간단하게 공부한 바로는
[LuaCallCSharp] : 이 클래스가 Lua 스크립트에서 호출될 수 있는 C# 메서드를 가지고 있음을 XLua에 알려줘요.
TextAsset luaScript: 이 변수는 실행할 Lua 스크립트를 저장하는 텍스트 파일을 참조해요.
static LuaEnv luaEnv: 이 변수는 모든 Lua 동작이 하나의 LuaEnv를 공유할 수 있도록 하는 XLua의 LuaEnv 클래스의 인스턴스를 저장해요. internal로 선언되어 있기 때문에, 같은 어셈블리 내에서만 사용 가능해요.
Action luaStart, luaUpdate, luaOnDestroy: 이 변수들은 각각 Lua 스크립트에서 가져온 start(), update(), ondestroy() 함수를 저장해요. 이 변수들은 Lua 스크립트에서 해당 함수가 정의되어 있지 않은 경우에도 null 값을 가질 수 있으며, 이러한 경우에는 해당 함수를 호출하지 않아요.
LuaTable scriptEnv: 스크립트가 실행될 때 생성된 Lua 환경을 저장하기 위한 LuaTable 변수를 선언해요
HelloWorld.lua.txt
function start()
print("lua start...")
end
function update()
print("lua update...")
end
function ondestroy()
print("lua destroy")
end
4. 테스트해보기
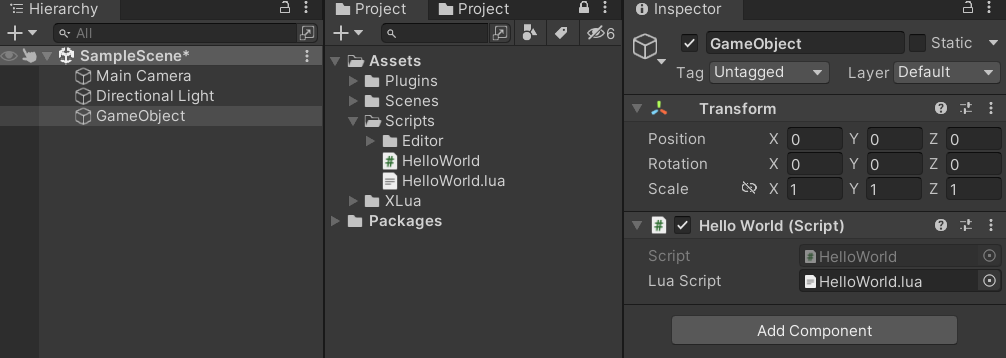
이제 씬에 게임오브젝트를 하나 만들고 HelloWorld.cs를 넣어준 다음 인스팩터 창에서 Lua Script부분에 작성한 Lua Scirpt를 어싸인해줘요.
그리고 프로젝트를 실행하면
아래처럼 Lua스크립트에서 print 메서드를 잘 호출하고 있음을 확인할 수 있어요.
또한 루아가 가진 타입스크립트에 특징인데 중간에 루아 스크립트를 수정하고 저장하면 프로젝트를 껐다키지 않아도 바로 반영이 돼요.
이걸 확인하려고 'G'키를 누를 때마다 루아스크립트가 실행 중이지 않다면 실행되게 코드를 작성했어요.
이 기능이 루아가 가진 큰 장점 중 하나라서 지금은 간단한 디버그만 찍어봤지만 다양한 작업을 할 수 있을 거라 공부해 볼 가치가 있다고 생각해요.
유니티에서 오브젝트를 생성하기 위해서는 Instantiate를 사용하고 삭제할 때는 Destroy를 사용해요.
하지만 Instantiate, Destroy 이 두 함수는 상당히 비용을 크게 먹는다는 것을 구글링을 해보면 알 수 있어요.
Instantiate(오브젝트 생성)은 메모리를 새로 할당하고 리소스를 로드하는 등의 초기화 과정이 필요하고, Destroy(오브젝트 파괴)는 파괴 이후에 발생하는 가비지 컬렉팅으로 인한 프레임 드랍이 발생할 수 있어요.
그렇다면 플레이어의 총알과 같이 자주 생성되고 삭제되는 오브젝트들이 있을 경우 치명적일 수 있는 거죠. 이때 사용할 수 있는 것이 오브젝트 풀링이에요. 자주 사용하는 오브젝트를 미리 생성해 놓고 이걸 사용할 때마다 새로 생성 삭제 하는 것 이 아닌 사용할 때는 오브젝트풀한테 빌려서 사용하고 삭제할 때는 오브젝트풀한테 돌려줌으로써 단순하게 오브젝트를 활성화 비활성화 만 하는 개념이에요.
유니티에서 오브젝트 풀링을 처음부터 지원하진 않았어요. 그렇기에 오브젝트 풀링을 구현하는 방법이 사람마다 달랐으며 성능도 달랐을 거라고 생각돼요. 하지만 지금은 유니티에서 오브젝트 풀링을 공식적으로 지원해요. 이 글은 유니티에서 공식적으로 제공하는 오브젝트 풀링 사용방법에 대해서 정리하는 글이에요.
2. 기본 프로젝트 세팅
간단하게 플레이어가 움직이고 플레이어가 총알을 발사하는 프로젝트를 만들어줘요.
Player.cs
using UnityEngine;
public class Player : MonoBehaviour
{
public float speed = 1f;
public Transform bulletSpawnPoint;
public GameObject bulletPrefab;
void Update()
{
if (Input.GetKeyDown(KeyCode.Space))
{
var bulletGo = Instantiate(bulletPrefab);
bulletGo.transform.position = this.bulletSpawnPoint.position;
}
// 가로 이동 반환값 : LeftArrow = -1 RightArrow = 1
var h = Input.GetAxisRaw("Horizontal");
// 세로 이동 반환값 : DownArrow = -1 UpArrow = 1
var v = Input.GetAxisRaw("Vertical");
//단위 벡터 (크기가 1인 벡터)
var dir = new Vector3(h, v, 0).normalized;
this.transform.Translate(dir * this.speed * Time.deltaTime);
}
}
플레이어가 이동하면서 space키를 누르면 총알을 발사하는 간단한 코드예요.
Bullet.cs
using UnityEngine;
public class Bullet : MonoBehaviour
{
public float speed = 5f;
void Update()
{
// 총알이 많이 날라가면 삭제 해주기
if (this.transform.position.y > 5)
{
Destroy(this.gameObject);
}
this.transform.Translate(Vector3.up * this.speed * Time.deltaTime);
}
}
총알이 생성되고 나서 위로 계속 올라가다가 일정 위치 이상으로 올라가면 삭제되는 간단한 코드예요.
간단하게 Circle 오브젝트에 빨간색을 넣어 만든 Bullet오브젝트는 프리팹으로 만들고 씬에선 삭제해 줘요
다음으로 Square 오브젝트에 검은색을 넣고 총알이 스폰될 위치를 잡아주고 이 위치와 총알 프리팹을 어싸인해 줘요.
3. 유니티 오브젝트 풀링 사용하기
이제 이 기존 코드를 유니티에서 제공하는 오브젝트 풀링을 사용하는 방식으로 바꿔볼게요.
바꾸기 전 오브젝트 풀링을 구현해 줘요.
ObjectPoolManager.cs
using UnityEngine;
using UnityEngine.Pool;
public class ObjectPoolManager : MonoBehaviour
{
public static ObjectPoolManager instance;
public int defaultCapacity = 10;
public int maxPoolSize = 15;
public GameObject bulletPrefab;
public IObjectPool<GameObject> Pool { get; private set; }
private void Awake()
{
if (instance == null)
instance = this;
else
Destroy(this.gameObject);
Init();
}
private void Init()
{
Pool = new ObjectPool<GameObject>(CreatePooledItem, OnTakeFromPool, OnReturnedToPool,
OnDestroyPoolObject, true, defaultCapacity, maxPoolSize);
// 미리 오브젝트 생성 해놓기
for (int i = 0; i < defaultCapacity; i++)
{
Bullet bullet = CreatePooledItem().GetComponent<Bullet>();
bullet.Pool.Release(bullet.gameObject);
}
}
// 생성
private GameObject CreatePooledItem()
{
GameObject poolGo = Instantiate(bulletPrefab);
poolGo.GetComponent<Bullet>().Pool = this.Pool;
return poolGo;
}
// 사용
private void OnTakeFromPool(GameObject poolGo)
{
poolGo.SetActive(true);
}
// 반환
private void OnReturnedToPool(GameObject poolGo)
{
poolGo.SetActive(false);
}
// 삭제
private void OnDestroyPoolObject(GameObject poolGo)
{
Destroy(poolGo);
}
}
이제 Bullet 오브젝트는 ObjectPoolManager가 생성하고 사용할 때마다 ObjectPoolManager가 관리하고 있는 Bullet 오브젝트를 받아서 사용할 수 있는 코드예요.
기존 Bullet 코드를 바꿔줘요.
Bullet.cs
using UnityEngine;
using UnityEngine.Pool;
public class Bullet : MonoBehaviour
{
public IObjectPool<GameObject> Pool { get; set; }
public float speed = 5f;
void Update()
{
// 총알이 많이 날라가면 삭제 해주기
if (this.transform.position.y > 5)
{
// 이제 자신이 Destroy를 하지 않는다.
//Destroy(this.gameObject);
// 오브젝트 풀에 반환
Pool.Release(this.gameObject);
}
this.transform.Translate(Vector3.up * this.speed * Time.deltaTime);
}
}
Player도 바꿔줘요.
using UnityEngine;
public class Player : MonoBehaviour
{
public float speed = 1f;
public Transform bulletSpawnPoint;
void Update()
{
if (Input.GetKeyDown(KeyCode.Space))
{
// 총알생성을 플레이어가 하지 않는다.
//var bulletGo = Instantiate(bulletPrefab);
// 오브젝트풀 에서 빌려오기
var bulletGo = ObjectPoolManager.instance.Pool.Get();
bulletGo.transform.position = this.bulletSpawnPoint.position;
}
// 가로 이동 반환값 : LeftArrow = -1 RightArrow = 1
var h = Input.GetAxisRaw("Horizontal");
// 세로 이동 반환값 : DownArrow = -1 UpArrow = 1
var v = Input.GetAxisRaw("Vertical");
//단위 벡터 (크기가 1인 벡터)
var dir = new Vector3(h, v, 0).normalized;
this.transform.Translate(dir * this.speed * Time.deltaTime);
}
}
이제 프로젝트를 시작하면 오브젝트를 미리 최소 정해진 수만큼 만들어 놓고 플레이어가 요청할떄마다 대여해서 사용할 거예요.
4. 오브젝트 여러 개 관리하기
지금까지는 총알 1개만 관리하는 거였다면 여러 종류의 오브젝트를 관리하는 오브젝트풀을 관리할 수 있어야 실용성이 있을 거예요.
그래서 저는 오브젝트풀을 관리하는 딕셔너리를 선언해서 외부에서는 오브젝트풀매니저에게 오브젝트를 요청만 하면 매니저가 해당 오브젝트에 해당하는 오브젝트풀에 접근해서 오브젝트를 받아서 넘겨주는 방식으로 구현했어요.
먼저 오브젝트풀을 관리하기 위해선 오브젝트풀에서 사용할 프리팹과 몇 개를 생성할지 count를 알아야 해요. 이걸 딕셔너리로 관리할 거 기 때문에 key값으로 사용할 오브젝트네임까지 받는 클래스를 선언했어요.
[System.Serializable]
private class ObjectInfo
{
// 오브젝트 이름
public string objectName;
// 오브젝트 풀에서 관리할 오브젝트
public GameObject perfab;
// 몇개를 미리 생성 해놓을건지
public int count;
}
이렇게 하고 오브젝트 매니저에게 할당하면 아래처럼 오브젝트풀에 등록할 오브젝트들을 등록할 수 있어요.
그리고 저는 딕셔너리를 2개와 String 변수 하나를 선언했는데
// 생성할 오브젝트의 key값지정을 위한 변수
private string objectName;
// 오브젝트풀들을 관리할 딕셔너리
private Dictionary<string, IObjectPool<GameObject>>
ojbectPoolDic = new Dictionary<string, IObjectPool<GameObject>>();
// 오브젝트풀에서 오브젝트를 새로 생성할때 사용할 딕셔너리
private Dictionary<string, GameObject> poolGoDic = new Dictionary<string, GameObject>();
objectPoolDic 은 오브젝트풀을 관리하기 위한 딕셔너리라면 poolGoDIc은 왜 필요하냐면요
처음에 오브젝트풀에서 오브젝트를 생성할 때 어떤 오브젝트를 생성해야 하는지를 알 수가 없어요. 그렇기 때문에 생성해야 하는 오브젝트들을 objecgtName을 key값으로 갖게 하고 프리팹들을 저장해 놓고 풀에서 오브젝트를 새로 생성할 때 생성할 objecgtName key값에 해당하는 poolGoDic에 접근해서 오브젝트를 생성하는 거예요.
또한 보시면 이젠 Bullet 스크립트가 아니라 PoolAble 스크립트에 접근해서 Pool을 지정해주고 있는데 PoolAble 스크립트는 오브젝트풀을 사용할 오브젝트들이 모두 상속받게 해서 이 스크립트를 상속받은 오브젝트들만 오브젝트풀에 등록할 수 있게 했어요.
그래서 PoolAble 스크립트엔 그냥 자신이 돌려줘야 할 Pool을 저장할 프로퍼티와 자신의 게임 오브젝트를 넘겨줄 ReleaseObject 메서드만 정의를 해두면 돼요.
PoolAble.cs
using UnityEngine;
using UnityEngine.Pool;
public class PoolAble : MonoBehaviour
{
public IObjectPool<GameObject> Pool { get; set; }
public void ReleaseObject()
{
Pool.Release(gameObject);
}
}
Bullet.cs
using UnityEngine;
public class Bullet : PoolAble
{
public float speed = 5f;
void Update()
{
// 총알이 많이 날라가면 삭제 해주기
if (this.transform.position.y > 5)
{
// 오브젝트 풀에 반환
ReleaseObject();
}
this.transform.Translate(Vector3.up * this.speed * Time.deltaTime);
}
}
ObjectPoolManager.cs
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Pool;
public class ObjectPoolManager : MonoBehaviour
{
[System.Serializable]
private class ObjectInfo
{
// 오브젝트 이름
public string objectName;
// 오브젝트 풀에서 관리할 오브젝트
public GameObject perfab;
// 몇개를 미리 생성 해놓을건지
public int count;
}
public static ObjectPoolManager instance;
// 오브젝트풀 매니저 준비 완료표시
public bool IsReady { get; private set; }
[SerializeField]
private ObjectInfo[] objectInfos = null;
// 생성할 오브젝트의 key값지정을 위한 변수
private string objectName;
// 오브젝트풀들을 관리할 딕셔너리
private Dictionary<string, IObjectPool<GameObject>> ojbectPoolDic = new Dictionary<string, IObjectPool<GameObject>>();
// 오브젝트풀에서 오브젝트를 새로 생성할때 사용할 딕셔너리
private Dictionary<string, GameObject> goDic = new Dictionary<string, GameObject>();
private void Awake()
{
if (instance == null)
instance = this;
else
Destroy(this.gameObject);
Init();
}
private void Init()
{
IsReady = false;
for (int idx = 0; idx < objectInfos.Length; idx++)
{
IObjectPool<GameObject> pool = new ObjectPool<GameObject>(CreatePooledItem, OnTakeFromPool, OnReturnedToPool,
OnDestroyPoolObject, true, objectInfos[idx].count, objectInfos[idx].count);
if (goDic.ContainsKey(objectInfos[idx].objectName))
{
Debug.LogFormat("{0} 이미 등록된 오브젝트입니다.", objectInfos[idx].objectName);
return;
}
goDic.Add(objectInfos[idx].objectName, objectInfos[idx].perfab);
ojbectPoolDic.Add(objectInfos[idx].objectName, pool);
// 미리 오브젝트 생성 해놓기
for (int i = 0; i < objectInfos[idx].count; i++)
{
objectName = objectInfos[idx].objectName;
PoolAble poolAbleGo = CreatePooledItem().GetComponent<PoolAble>();
poolAbleGo.Pool.Release(poolAbleGo.gameObject);
}
}
Debug.Log("오브젝트풀링 준비 완료");
IsReady = true;
}
// 생성
private GameObject CreatePooledItem()
{
GameObject poolGo = Instantiate(goDic[objectName]);
poolGo.GetComponent<PoolAble>().Pool = ojbectPoolDic[objectName];
return poolGo;
}
// 대여
private void OnTakeFromPool(GameObject poolGo)
{
poolGo.SetActive(true);
}
// 반환
private void OnReturnedToPool(GameObject poolGo)
{
poolGo.SetActive(false);
}
// 삭제
private void OnDestroyPoolObject(GameObject poolGo)
{
Destroy(poolGo);
}
public GameObject GetGo(string goName)
{
objectName = goName;
if (goDic.ContainsKey(goName) == false)
{
Debug.LogFormat("{0} 오브젝트풀에 등록되지 않은 오브젝트입니다.", goName);
return null;
}
return ojbectPoolDic[goName].Get();
}
}
Player.cs
using UnityEngine;
public class Player : MonoBehaviour
{
public float speed = 1f;
public Transform bulletSpawnPoint;
void Update()
{
if (Input.GetKeyDown(KeyCode.Alpha1))
{
// 오브젝트풀 에서 빌려오기
var bulletGo = ObjectPoolManager.instance.GetGo("BulletRed");
bulletGo.transform.position = this.bulletSpawnPoint.position;
}
if (Input.GetKeyDown(KeyCode.Alpha2))
{
// 오브젝트풀 에서 빌려오기
var bulletGo = ObjectPoolManager.instance.GetGo("BulletGreen");
bulletGo.transform.position = this.bulletSpawnPoint.position;
}
if (Input.GetKeyDown(KeyCode.Alpha3))
{
// 오브젝트풀 에서 빌려오기
var bulletGo = ObjectPoolManager.instance.GetGo("BulletBlue");
bulletGo.transform.position = this.bulletSpawnPoint.position;
}
// 가로 이동 반환값 : LeftArrow = -1 RightArrow = 1
var h = Input.GetAxisRaw("Horizontal");
// 세로 이동 반환값 : DownArrow = -1 UpArrow = 1
var v = Input.GetAxisRaw("Vertical");
//단위 벡터 (크기가 1인 벡터)
var dir = new Vector3(h, v, 0).normalized;
this.transform.Translate(dir * this.speed * Time.deltaTime);
}
}
5. 완성
이렇게 한번 만들어두면 나중엔 ObjectPoolManager.instance.GetGo(가져올 오브젝트이름)으로 접근해서 사용할 수 있어요
마지막으로 sortFiles를 정렬한 후에 fullName만 따로 빼서 return 하면 정답처리가 돼요.
bool Compare(File file1, File file2)
{
// 헤드 먼저 비교
if (file1.head > file2.head)
return false;
else if (file1.head < file2.head)
return true;
// 헤드가 같다면 number 비교
if (file1.number > file2.number)
return false;
else if (file1.number < file2.number)
return true;
// number 까지 같다면 들어온 순서 유지
return file1.inputNumber < file2.inputNumber;
}
3. 함수 설명
bool Compare(File file1, File file2)
문제에서 요구하는 정렬 순서를 정의하기 위한 함수예요.
bool IsNumber(char c)
해당 문자가 숫자인지 체크하는 함수예요.
4. 코드
#include <algorithm>
#include <string>
#include <vector>
using namespace std;
struct File
{
string fullName;
string head;
int number;
int inputNumber;
};
bool Compare(File file1, File file2)
{
// 헤드 먼저 비교
if (file1.head > file2.head)
return false;
else if (file1.head < file2.head)
return true;
// 헤드가 같다면 number 비교
if (file1.number > file2.number)
return false;
else if (file1.number < file2.number)
return true;
// number 까지 같다면 들어온 순서 유지
return file1.inputNumber < file2.inputNumber;
}
// 문자가 숫자인지 체크하는 함수
bool IsNumber(char c)
{
if (c >= '0' && c <= '9')
return true;
else
return false;
}
vector<string> solution(vector<string> files)
{
vector<File> sortFiles;
vector<string> answer;
int cnt = 0;
for (auto file : files)
{
File tempFile;
tempFile.fullName = file;
int idx = 0;
for (; idx < file.size(); idx++)
{
// 문자열 체크
if (!IsNumber(file[idx]))
{
if (file[idx] >= 'A' && file[idx] <= 'Z')
tempFile.head += (file[idx] + 32);
else
tempFile.head += file[idx];
}
else
{
break;
}
}
string strNumber;
for (; idx < file.size(); idx++)
{
if (IsNumber(file[idx]))
strNumber += file[idx];
else
break;
}
tempFile.number = stoi(strNumber);
tempFile.inputNumber = cnt;
cnt++;
sortFiles.push_back(tempFile);
}
sort(sortFiles.begin(), sortFiles.end(), Compare);
for (auto sortFile : sortFiles)
answer.push_back(sortFile.fullName);
return answer;
}
코드편집툴로 Visual Studio community를 정말 오래 썼는데 회사에선 Rider나 VSCode를 사용하더라고요.
익숙한 Visual Studio community를 쓰려고 하였지만 개인이 사용할 때는 무료인데 회사에선 완전무료가 아니고 조건이 붙어요. 아래는 'MICROSOFT VISUAL STUDIO COMMUNITY 2022' 라이선스 설명이에요.
개별 라이선스 : 판매 또는 다른 목적으로 고유한 응용 프로그램에 개별적으로 작업하는 경우 이러한 응용 프로그램의 개발 및 테스트를 목적으로 소프트웨어를 사용할 수 있습니다.
조직 라이선스 : 조직인 경우 귀사의 사용자는 다음과 같이 소프트웨어를 사용할 수 있습니다:
i. 귀하의 사용자는 사용자의 수와 상관없이 OSI(오픈 소스 이니셔티브)에서 승인한 오픈 소스 소프트웨어 라이선스에 따라 출시된 응용 프로그램의 개발 및 테스트를 목적으로 소프트웨어를 사용할 수 있습니다.
ii. 귀사의 사용자는 사용자의 수와 상관없이 Visual Studio에 대한 확장 기능의 개발 및 테스트를 목적으로 소프트웨어를 사용할 수 있습니다.
iii. 귀사의 사용자는 사용자의 수와 상관없이 Windows 운영 체제에 대한 장치 드라이버의 개발 및 테스트를 목적으로 소프트웨어를 사용할 수 있습니다.
iv. 귀사의 사용자는 사용자의 수와 상관없이 Microsoft SQL Server Data Tools 또는 "Microsoft Analysis Services Projects", "Microsoft Reporting Services Projects" 또는 "SQL Server Integration Services Projects" 확장 기능을 사용하여 Microsoft SQL Server 데이터베이스 프로젝트 또는 Analysis Services, Reporting Services, Power BI Report Server 또는 Integration Services 프로젝트를 개발할 때 Microsoft SQL Server 개발에만 해당 소프트웨어를 사용할 수 있습니다.
v. 귀사의 사용자는 사용자의 수와 상관없이 강의실 교육(온라인 또는 직접)의 일환으로 응용 프로그램의 개발 및 테스트를 목적으로 또는 교육 연구 수행을 목적으로 소프트웨어를 사용할 수 있습니다.
vi. 위의 사항에 해당하지 않으며 귀사가 기업(아래에 정의됨)이 아닌 경우 최대 5명의 귀사의 개별 사용자가 응용 프로그램의 개발 및 테스트를 목적으로 동시에 소프트웨어를 사용할 수 있습니다.
vii. 귀하가 기업인 경우에는 그 직원 및 계약자가 응용 프로그램의 개발 또는 테스트를 목적으로 소프트웨어를 사용할 수 없습니다. 단, 상기 허용된 범위 내에서 (i) 오픈 소스, (ii) Visual Studio 확장, (iii) Windows 운영 체제를 위한 장치 드라이버, (iv) SQL Server 개발, 그리고 (v) 교육 목적은 여기서 제외됩니다.
"기업"이란 통칭 (a) 250대보다 많은 PC 또는 250명보다 많은 사용자가 있거나 (b) 연간 매출이 미화 1백만 달러(또는 다른 통화에서 이와 동등한 금액) 이상을 초과하는 조직 및 그 계열사이며, "계열사"란 조직을 통제하거나(과반수 소유권을 통해) 조직의 통제를 받거나 조직과 공동 통제권을 가지고 있는 모든 업체를 의미합니다.
#define INF 1000000000
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int N, M;
int startIndex, endIndex;
vector <pair<int, int>> graph[1001];
int distances[1001];
void Dijkstra(int start)
{
distances[start] = 0;
priority_queue<pair<int, int>> pq;
pq.push(make_pair(start, 0));
while (!pq.empty())
{
int current = pq.top().first;
int distance = -pq.top().second;
pq.pop();
//최단 거리가 아닌 경우 스킵
if (distances[current] < distance) continue;
for (int i = 0; i < graph[current].size(); i++)
{
// 선택된 노드의 인접 노드
int next = graph[current][i].first;
// 선택된 노드를 인접 노드로 거쳐서 가는 비용
int nextDistance = distance + graph[current][i].second;
// 기존의 최소 비용보다 더 저렴하다면 교체.
if (nextDistance < distances[next])
{
distances[next] = nextDistance;
pq.push(make_pair(next, -nextDistance));
}
}
}
}
void Solution()
{
for (int i = 1; i <= N; i++)
distances[i] = INF;
Dijkstra(startIndex);
cout << distances[endIndex] << endl;
}
void Input()
{
cin >> N >> M;
for (int i = 0; i < M; i++)
{
int from;
int to;
int distance;
cin >> from >> to >> distance;
graph[from].push_back(make_pair(to, distance));
}
cin >> startIndex >> endIndex;
}
int main()
{
Input();
Solution();
return 0;
}
#define INF 1000000000
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int V, E;
int startIndex;
vector <pair<int, int>> graph[20001];
int distances[20001];
void Dijkstra(int start)
{
distances[start] = 0;
priority_queue<pair<int, int>> pq;
pq.push(make_pair(0, start));
while (!pq.empty())
{
int distance = -pq.top().first;
int current = pq.top().second;
pq.pop();
//최단 거리가 아닌 경우 스킵
if (distances[current] < distance) continue;
for (int i = 0; i < graph[current].size(); i++)
{
// 선택된 노드를 인접 노드로 거쳐서 가는 비용
int nextDistance = distance + graph[current][i].first;
// 선택된 노드의 인접 노드
int next = graph[current][i].second;
// 기존의 최소 비용보다 더 저렴하다면 교체.
if (nextDistance < distances[next])
{
distances[next] = nextDistance;
pq.push(make_pair(-nextDistance, next));
}
}
}
}
void Solution()
{
for (int i = 1; i <= V; i++)
distances[i] = INF;
Dijkstra(startIndex);
for (int i = 1; i <= V; i++)
{
if (distances[i] != INF)
cout << distances[i] << "\n";
else
cout << "INF" << "\n";
}
}
void Input()
{
cin >> V >> E;
cin >> startIndex;
for (int i = 0; i < E; ++i)
{
int from;
int to;
int distance;
cin >> from >> to >> distance;
graph[from].push_back(make_pair(distance, to));
}
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
Input();
Solution();
return 0;
}
코루틴은 은근히 쓰레기 메모리(가비지)를 자주 생성해요. 코루틴을 자주 사용하는 로직에서 이를 최적화하지 않는다면 GC의 collect에서 프레임이 상당히 떨어질 수 있어요..
코루틴에서 가비지가 생성되는 주요한 부분으로는 크게 두 가지가 있어요..
- StartCoroutine
- YieldInstruction
StartCoroutine 메서드를 호출할 때 유니티가 해당 코루틴을 관리하기 위해 엔진내부에서 인스턴스가 생성되며 이때 이것이 가비지가 된다고 해요. StartCoroutine은 유니티 엔진 내부의 코드이기 때문에 이를 최적화하는 것은 쉽지 않기 때문에 코루틴 기능을 직접 제작하거나 비슷한 기능을 제공하는 에셋 More Effective Coroutine을 사용해야 한다고 해요.
웬만하면 최소한으로 StartCoroutine을 사용해야 할 것 같아요.
그렇다면 저희가 최적화를 건드릴 수 있는 부분은 YieldInstruction가 남아있어요. YieldInstruction 이거는 아래와 같은 종류들이 있어요.
여기서 yield구문 자체는 가비지를 생성하지 않지만 new가 붙는 yield return new WaitForSeconds(float) 같은 것들이 가비지가 생성이 되기 때문에 캐싱을 해주는 게 좋아요.
using System.Collections;
using UnityEngine;
public class Test2Main : MonoBehaviour
{
private void Start()
{
StartCoroutine(this.WaitForSecondsTestImpl());
StartCoroutine(this.WaitForEndOfFrameTestImpl());
StartCoroutine(this.WaitForFixedUpdateTestImpl());
}
private IEnumerator WaitForSecondsTestImpl()
{
while (true)
{
yield return new WaitForSeconds(0.01f);
}
}
private IEnumerator WaitForEndOfFrameTestImpl()
{
while (true)
{
yield return new WaitForEndOfFrame();
}
}
private IEnumerator WaitForFixedUpdateTestImpl()
{
while (true)
{
yield return new WaitForFixedUpdate();
}
}
}
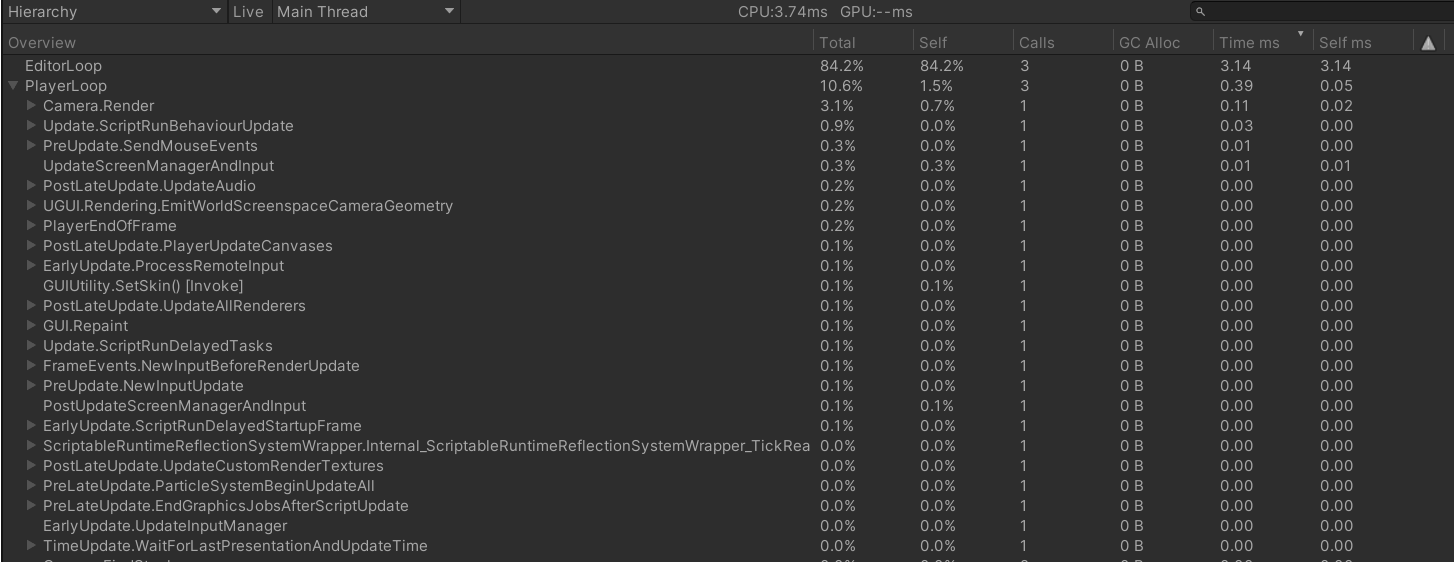
스샷을 보시면 프레임이 끝날 때마다 WaitForEndOfFrameTestImpl에서 가비지가 생성되고, FixedFrame이 끝날 때마다 WaitForFixedUpdateTestImpl에서 가비지가 생성되고, 지정한 시간이 지날 때마다 WaitForSecondsTestImpl에서 가비지가 생성이 되고 있는 것을 볼 수 있어요.
이때 캐싱을 할 때 WaitForEndOfFrame, WaitForFixedUpdate은 고정된 값이기에 한 번만 생성해 놓으면 되지만 WaitForSeconds처럼 여러 개의 Seconds가 필요할 때엔 고정된 값이 아니어서 제가 참고한 사이트에선 딕셔너리에 Seconds를 Key로 넣어놓고 값에 Seconds에 해당하는 WaitForSeconds를 넣어놓는 형식으로 캐싱을 했어요.
이때 기존에 있는 Key인지 검사하는 과정에서 딕셔너리에 TryGetValue를 사용할 때 박싱이 일어나는 것 때문에 IEqualityComparer를 구현해서 딕셔너리를 생성할 때 object형식으로 비교하는 게 아닌 제네릭형식으로 비교하는 것을 직접 만드셨던데
이테스트를 한 이유는 코루틴 최적화를 알아보던 도중 WaitForSeconds(seconds)를 캐싱하려면 딕셔너리에 seconds를 넣어두고 기존에 사용한 적이 있으면 캐싱한 WaitForSeconds를 반환하고 사용한 적이 없으면 딕셔너리에 해당 seconds를 넣어서 캐싱하는 기법을 사용한다고 해요.
이때 사용한 적이 있는지를 확인하기 위해 딕셔너리에 TryGetValue를 사용하는 과정 중 박싱이 발생할 수 있다고 하여 IEqualityComparer 인터페이스를 새로 구현하여 딕셔너리에 비교 연산자로 넣어줘야 한다고 해서 object 형식이 아닌 비교하려는 자료형을 선언하여 박싱이 일어나지 않게 해야 한다고 하는데 이 부분이 이해가 가지 않아서 테스트를 해봤어요.
C# 도큐먼트를 봤을 때는 object가 아닌 제네릭형식 TKey를 받아서 하고 있기 때문에 박싱이 일어나지 않을까 생각했어요.
제네릭 컬렉션도 방식이 발생할 수 있다 글에서 테스트한 프로파일링 결과예요 해당결과를 보면
DefaultComparer를 사용할 때 가비지 컬렉션이 발생하는것을 알 수 있어요.
저도 동일한 코드를 작성해서 테스트 해봤어요.
using System.Collections.Generic;
using UnityEngine;
public class StructTest : MonoBehaviour
{
public struct Struct
{
public int value;
public Struct(int value)
{
this.value = value;
}
}
private Dictionary<Struct, string> structDic = new Dictionary<Struct, string>();
private void Start()
{
for (int i = 0; i < 5; ++i)
{
structDic.Add(new Struct(i), i.ToString());
}
}
void Update()
{
string str;
for (int i = 0; i < 5; ++i)
{
structDic.TryGetValue(new Struct(i), out str);
}
}
}
using System.Collections.Generic;
using UnityEngine;
public class IntTest : MonoBehaviour
{
private Dictionary<int, string> intDic = new Dictionary<int, string>();
void Start()
{
for (int i = 0; i < 5; ++i)
{
intDic.Add(i, i.ToString());
}
}
void Update()
{
string str;
for (int i = 0; i < 5; ++i)
{
intDic.TryGetValue(i, out str);
}
}
}
using System.Collections.Generic;
using UnityEngine;
public class EnumTest : MonoBehaviour
{
public enum Enums
{
Enums0,
Enums1,
Enums2,
Enums3,
Enums4,
}
Dictionary<Enums, string> enumDic = new Dictionary<Enums, string>();
void Start()
{
for (int i = 0; i < 5; ++i)
{
enumDic.Add((Enums)i, i.ToString());
}
}
void Update()
{
string str;
for (int i = 0; i < 5; ++i)
{
enumDic.TryGetValue((Enums)i, out str);
}
}
}
저 또한 가비지가 생기고 있으나 Enum에선 생기지 않고 있는 것을 볼 수 있고 DefaultComparer는 확인할 수 없었어요. 다만 이때 생기는 가비지 또한 박싱때문에 생긴 다기보단
비교를 할 때 new 키워드를 사용해서 인스턴스를 새로 만들고 있어서 가비지가 생기는 게 아닌가란 생각이 들었어요. 아마 위에 테스트 당시보다 유니티 버전이 오르고 C# 버전도 올라서 그런 게 아닐까 조심스럽게 예상해 봐요.
이제 코루틴 최적화도 테스트해 볼 건데 제 예상엔 IEqualityComparer는 구현 안 해도 캐싱하는데 문제가 없지 않을까 미리 예상해 봐요.
저는 유니티 버전 2021.3.5f1, .NET Standard 2.1, Visual Studio 2019 환경에서 테스트했어요.
다익스트라 알고리즘은 음의 간선이 없을 때 사용할 수 있는 하나의 정점에서 다른 모드 정점으로 가는 최단 경로를 구할 때 사용하는 알고리즘이에요. 현실 세계에선 음의 간선이 없기 때문에 현실세계에서도 사용하기 적합한 알고리즘 중 하나예요.
다익스트라 알고리즘은 시작 노드부터 인접노드들을 방문하며 최단 거리를 구할 때 이전에 구했던 최단 거리 정보를 재사용하는 특징이 있어요. 이때 인접노드가 여러 개가 있다면 가장 낮은 cost를 갖는 노드부터 방문하며 cost를 갱신하게 구현해 봤어요.
구현해야 하는 내용들은 다음과 같아요.
1. 출발 노드 세팅.
2. 출발 노드를 기준으로 각 노드의 최소 비용을 세팅.
3. 방문하지 않는 노드 중 가장 cost가 적은 노드 선택.
4. 해당 노드를 거쳐서 특정한 노드로 가는 경우를 고려하여 최소 비용을 갱신.
5. 3 ~ 4 반복
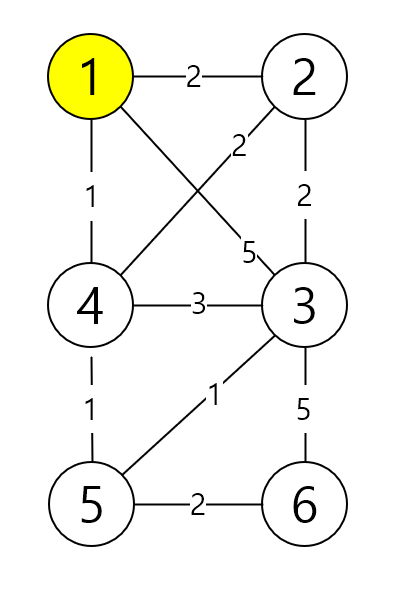
아래와 같은 그래프가 있다고 생각하고 진행해 볼게요.
1. 출발 노드는 1번 노드부터 한다고 가정했어요.
2. 출발노드를 기준으로 각 노드의 최소비용을 세팅해요.
현재 1번 노드는 2, 3, 4 하고만 연결이 되어 있기 때문에 다음과 같은 값을 갖고 있어요.
이 중 에서 이제 4번 노드의 cost가 가장 낮기 때문에 4번 노드부터 탐색합니다.
4번 노드에서 갈 수 있는 노드들은 1, 2, 3, 5번 노드가 있어요.
이것들을 1번에서 4번까지 가는 cost(1) + 각 노드까지 가는 cost가 기존에 등록되어 있는 값들보다 저렴하게 갈 수 있는지를 체크하는 거예요.
1번 노드 1 + 1 < 0 X
2번 노드 1 + 2 < 2 X
3번 노드 1 + 3 < 5 O
5번 노드 1 + 1 < INF O
다음과 같이 더 낮은 값이 있으면 distances를 갱신해 줘요.
방문 한 노드는 파란색으로 표현할게요
이제 방문 안 한 노드 중 가장 낮은 cost값을
갖는 노드는 2번과 5번이 있는데 이때는 앞에 인덱스부터 찾아요.
2번은 1, 3, 4 노드랑 연결이 되어 있네요.
1번 노드 2 + 2 < 0 X
3번 노드 2 + 2 < 2 X
4번 노드 2 + 2 < 1 X
갱신되는 노드가 없네요.
이제 5번 노드를 탐색해요.
5번 노드는 3, 4, 6 하고 연결이 되어 있네요.
3번 노드 2 + 1 < 4 O
4번 노드 2 + 1 < 1 X
6번 노드 2 + 2 < INF O
3, 6번 노드가 갱신이 일어났어요.
마찬가지로 3번과 6번 노드의 cost값이 같기 때문에 3번 노드부터 탐색을 해요.
3번 노드는 1, 2, 4, 5, 6 하고 연결이 되어 있네요. 모든 노드하고 연결이 되어 있어요.
1번 노드 3 + 5 < 0 X
2번 노드 3 + 2 < 2 X
4번 노드 3 + 3 < 1 X
5번 노드 3 + 1 < 2 X
6번 노드 3 + 5 < 4 X
갱신되는 노드가 없네요.
마지막 6번 노드는 3, 5 하고 연결이 되어 있네요.
3번 노드 4 + 5 < 0 X
5번 노드 4 + 2 < 2 X
이렇게 모든 노드 방문이 끝나면 1번 노드에서 각 노드까지 가는 최적의 cost를 구할 수 있어요.
#define INF 1000000000
#include <iostream>
#include <vector>
using namespace std;
int V, E;
int startIndex;
vector <pair<int, int>> graph[7];
int distances[7];
bool visit[7];
// 가장 최소 cost를 가지는 정점을 반환합니다.
int GetSmallIndex()
{
int min = INF;
int index = 0;
for (int i = 1; i <= V; i++)
{
if (distances[i] < min && !visit[i])
{
min = distances[i];
index = i;
}
}
return index;
}
void Dijkstra(int startIndex)
{
for (int i = 1; i <= V; i++)
{
distances[i] = INF;
}
// 2. 출발 노드를 기준으로 각 노드의 최소 비용을 세팅
for (int i = 0; i < graph[startIndex].size(); i++)
{
int vertex = graph[startIndex][i].second;
int cost = graph[startIndex][i].first;
distances[vertex] = cost;
}
distances[startIndex] = 0;
visit[startIndex] = true;
for (int i = 1; i <= V-1; i++)
{
// 3. 방문하지 않는 노드 중 가장 cost가 적은 노드 선택.
int current = GetSmallIndex();
visit[current] = true;
// 4. 해당 노드를 거쳐서 특정한 노드로 가는 경우를 고려하여 최소 비용을 갱신.
// 현재 연결된 노드중 가장 낮은 cost를 갖는 노드의 연결된 노드들을 확인
for (int j = 0; j < graph[current].size(); j++)
{
int vertex = graph[current][j].second;
// distances[vertex] = 현재 기록된 최소 cost.
// graph[current][j].first = 현재 연결된 노드의 인접 노드의 cost
// 현재 기록된 최소 cost보다 (현재 연결된 노드에서 인접노드로 가기 위한 cost + 현재 노드까지 오기 위한 cost)가 크다면 cost 갱신해 주기
if (distances[vertex] > graph[current][j].first + distances[current])
distances[vertex] = graph[current][j].first + distances[current];
}
}
}
void Input()
{
cin >> V >> E;
for (int i = 0; i < E; i++)
{
int from;
int to;
int distance;
cin >> from >> to >> distance;
graph[from].push_back(make_pair(distance, to));
graph[to].push_back(make_pair(distance, from));
}
// 1. 출발 노드 세팅.
cin >> startIndex;
}
int main()
{
Input();
Dijkstra(startIndex);
for (int i = 1; i <= V; i++)
{
cout << distances[i] << " ";
}
return 0;
}
// input
/*
6 10
1 2 2
1 3 5
1 4 1
2 3 3
2 4 2
3 4 3
3 5 1
3 6 5
4 5 1
5 6 2
1
*/
위코드는 다익스트라를 단순 구현 했을 경우예요.
하지만 이처럼 구현하게 되면
int GetSmallIndex()
{
int min = INF;
int index = 0;
for (int i = 1; i <= V; i++)
{
if (distances[i] < min && !visit[i])
{
min = distances[i];
index = i;
}
}
return index;
}
3. 방문하지 않는 노드 중 가장 cost가 적은 노드 선택 -> 과정에서 해당 부분처럼 간선이 없더라도 일단 모든 노드를 다 탐색하기에
시간 복잡도가 O(N^2)가 나와요. 이 말이 무슨 말이냐면 노드가 10000개고 간선이 2개밖에 없더라도 일단 코드는 10000*10000번 탐색을 하는 비효율 적인 코드예요.
#define INF 1000000000
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
int V, E;
int startIndex;
vector <pair<int, int>> graph[7];
int distances[7];
void Dijkstra(int startIndex)
{
for (int i = 1; i <= V; i++)
{
distances[i] = INF;
}
distances[startIndex] = 0;
priority_queue<pair<int, int>> pq;
pq.push(make_pair(0, startIndex));
while (!pq.empty())
{
// 3. 방문하지 않는 노드 중 가장 cost가 적은 노드 선택.
int distance = -pq.top().first;
int current = pq.top().second;
pq.pop();
//최단 거리가 아닌 경우 스킵
if (distances[current] < distance) continue;
// 4. 해당 노드를 거쳐서 특정한 노드로 가는 경우를 고려하여 최소 비용을 갱신.
// 현재 연결된 노드중 가장 낮은 cost를 갖는 노드의 연결된 노드들을 확인
for (int i = 0; i < graph[current].size(); i++)
{
// 선택된 노드를 인접 노드로 거쳐서 가는 비용
int nextDistance = distance + graph[current][i].first;
// 선택된 노드의 인접 노드
int next = graph[current][i].second;
// 기존의 최소 비용보다 더 저렴하다면 교체.
if (nextDistance < distances[next])
{
distances[next] = nextDistance;
// 방문할 수 있는 노드이므로 이노드들에서도 탐색 시작
pq.push(make_pair(-nextDistance, next));
}
}
}
}
void Input()
{
cin >> V >> E;
for (int i = 0; i < E; i++)
{
int from;
int to;
int distance;
cin >> from >> to >> distance;
graph[from].push_back(make_pair(distance, to));
graph[to].push_back(make_pair(distance, from));
}
// 1. 출발 노드 세팅.
cin >> startIndex;
}
int main()
{
Input();
Dijkstra(startIndex);
for (int i = 1; i <= V; i++)
{
cout << distances[i] << " ";
}
return 0;
}
// input
/*
6 10
1 2 2
1 3 5
1 4 1
2 3 3
2 4 2
3 4 3
3 5 1
3 6 5
4 5 1
5 6 2
1
*/
그래서 이렇게 연결이 된 부분들만 검사하는 즉 정점에 비해 간선이 적은 경우에도 대항할 수 있는 코드로 구현이 가능해요. 이렇게 될 때 시간 복잡도는 O(N * log N)이 나온다고 해요. priority_queue를 이용한 이유는 cost가 적은 노드부터 꺼내서 탐색하기 위해서 cost값에 -를 넣어서 넣게되면 cost가 작은 노드들이 가장 큰 값으로 정렬이 되기 때문에 사용했어요.